
CPU Spikes in Azure App Services
We recently ran into buggy behavior with the Azure load balancers which sit in front of an App Service and distribute the traffic between each server instance. It manifested as peaky CPU load on one of the horizontally scaled-out instances in the App Service Plan. At seemingly random times, monitoring alerts would fire for dropped requests and request latencies going over SLA thresholds. Each time, the source was the same; one of the app service instances was suffering extremely high CPU load.
Initial Triage
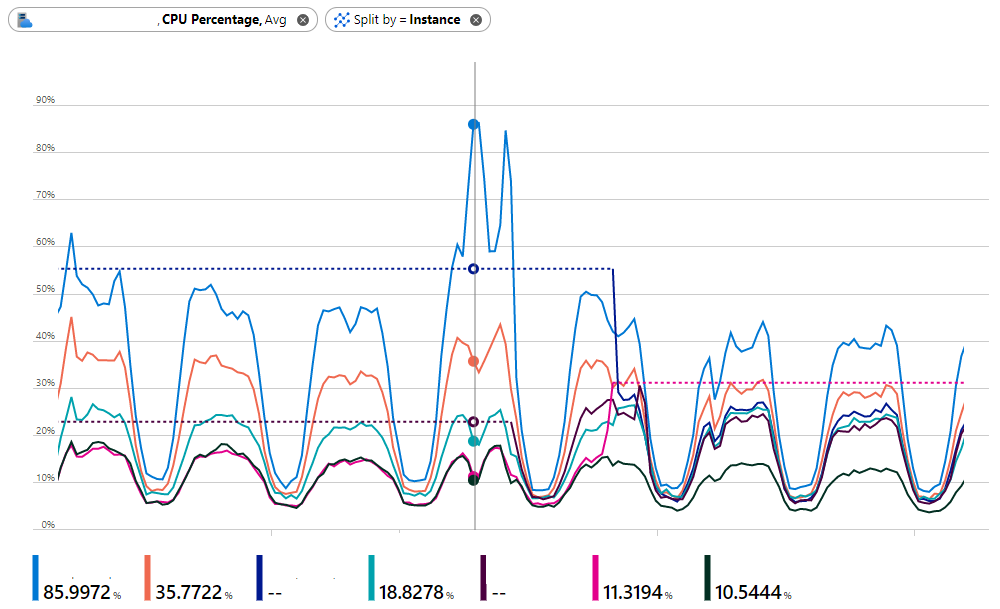
To compensate, we increased the number of instances to 5-6 S3 instances (4 CPU, 7 GB RAM, ~400 ACU) costing about €1500 p/m. With 5 instances you can still see imbalance in the above image. The blue server is peaking out at ~85% CPU utilization, while the pink & black instances are completely under utilized. At 4 instances this was even more pronounced and eventually the blue server would crumple under the load as the number of queued connections and requests increased.
This was bad! Aside from a server instance going down:
- The average CPU utilization for the service plan was still comparatively low so auto-scale rules weren’t being triggered to bring additional instances online.
- Manually added instances were still prone to the same uneven distribution as
pink&black. We were throwing a lot of money at the problem for little gain.
App Service Load Balancer “Logic”
At this point we escalated the issue to Azure Support
Hi Azure Support, you appear to have a problem with your load balancers!
They responded
Nah, we’re good, they’re working as expected, you appear to have a problem with your app!
Frustrating! But starting to make sense. Azure load balancers (both the PaaS product, and the those which sit in front of App Services) are network-level technology. They use a 5-tuple hash algorithm to decide where to route traffic based on:
- Source IP Address
- Source Port
- Destination IP Address
- Destination Port
- IP protocol number
It’s not a pure, random-distribution, round-robin approach. And it doesn’t take things into account like the Application & URL routes of the HTTP service been called.
Diving into App Insights
A little more digging and we get to the source of the issue. The app service plan was hosting 2 separate applications, with 2 very different CPU utilization profiles.
- Application A is an API service doing database calls, CosmosDB calls, and performing a lot of business rule processing on the retrieved data in each request. These were CPU intensive requests
- Application B is a very light-weight traffic redirection service. These request were extremely light on CPU utilization.
While the overall distribution of requests is being evenly spread across all the server instances, there is a very uneven distribution of Application traffic to each instance.
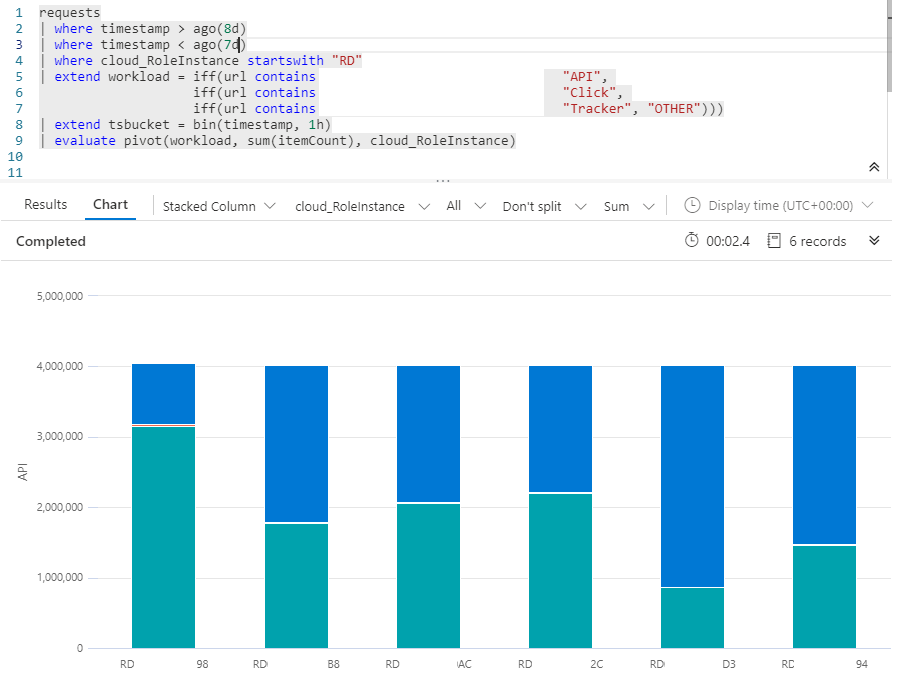
In the above bar chart the green segments are the light weight click & tracking requests. The blue segments are the CPU intensive API calls. For this 24 hour period, the 5th server, RD***D3 is getting hammered by CPU-intensive requests (accounting for > 75% of it’s request count) where as the 1st server, RD**98 spends most of it’s time serving simple static content and 302 redirects.
Separate the Apps
The solve was pretty obvious in hindsight, and is alluded to in a single line of Azure documentation
Isolate your app into a new app service plan when the app is resource intensive
Thankfully our API endpoints were already in two separate .NET projects, deployed to 2 separate app services. If they’d been different endpoints in the same project, this would have been a more time consuming solve. Moving an App Service to a different plan is straight forward within the same region and resource group.
First, we moved the CPU heavy API application into it’s own dedicated App Service Plan. Then we changed the scale up & scale out configuration for each of the two different app service plans to accommodate their specific CPU utilization profiles.
Old Configuration
Plan 1
Scale Up: S3 (4CPU / 7GB Ram / 400ACU)
Scale Out: 6
Running Cost: €1,500 p/m
New Configuration
Plan 1
Scale Up: P2v2 (2CPU / 7GB Ram / 420ACU)
Scale Out: 3
Running Cost: ~€750 p/m
Plan 2
Scale Up: P1v2 (1CPU / 3.5GB Ram / 210ACU)
Scale Out: 2
Running Cost: ~€250 p/m
With these changes we’re seeing a whole host of improvements
- CPU Utilization is more evenly distributed
- We’re making more efficient use of resources on a smaller number of instances
- Auto Scale rules based on Avg. CPU Utilization are working
- Fewer total instances are running equating to a 33% cost saving
Eoin Campbell