
Building BuyIrish.com
Over the past few days myself & a few colleagues have been chipping away at a little hackathon project to try and help drive consumers towards Irish retailers in the run into Xmas. The premise was simple. Could we use our existing knowledge and capabilities around product data acquisition and web crawling/scraping and create a search engine/aggregator site to allow a consumer to search for products and gift ideas (incl. price & availability) across lots of Irish retailers and product categories?
The result… https://buyirish.com
Gathering the Data
The first major challenge we had was acquiring the data. Typically, we’ll need to tailor our crawlers on a per-site basis. Is information available in the page source, or dynamically injected by javascript? How is that data presented? Do we need to tailor the parsers to identify specific places on the page to extract content? Do we need to get around anti-bot measures or use web proxies? Thankfully Alan & our DAX (Data Acquisition) team are really on the ball and they came up with a clever solution using a combination of services to gather the data in a fairly generic manner.
A master list of scraped datasets was maintained centrally and each time we added additional retailer, their data set was appended to this master list.This allowed us to build an extremely simple .NET Core console tool which performed the following logic
using var webClient = new WebClient();
var rJson = webClient.DownloadString(_masterListUri);
var r = JsonConvert.DeserializeObject<RetailerRoot>(rJson);
foreach (var retailer in r.Retailers)
{
var pJson = webClient.DownloadString(retailer.Uri);
var p = JsonConvert.DeserializeObject<Products>(pJson);
foreach(var product in p.Products)
{
//Send it to somewhere I guess ¯\_(ツ)_/¯
}
}
A Rough Design
We knew that to get this up and going quickly we didn’t want to start muddling around with a Azure SQL instance or have to start modelling and pushing migrations with something like Entity Framework to a relational db. And we already use CosmosDB extensively in our core platform. Our production APIs serve millions of requests daily from Cosmos so we knew it would be a good candidate for direct storage and could deal with requests at scale. BUT… we also knew that the equivalent of the following query wasn’t going to get great results from a relevancy point of view.
SELECT *
FROM data
WHERE data.ProductName LIKE '%term%'
OR data.Description LIKE '%term%'
OR data.Tags LIKE '%term%'
A little light bedtime reading later, and we thought we had our answer. We could bulk load the data directly into Cosmos and then point an Azure Cognitive Search instance at the CosmosDB container. ACS would keep it’s own index up to date based on a high-watermark timestamp check every 60 minutes. It would also give us the benefit of result relevancy scoring, and the ability to tweak the scoring profiles if needed.
Bulkloading into CosmosDB
Getting the data into Cosmos proved exceptionally simple with the new v3 Cosmos SDK. One of the first tests performed involved bulkload Upserting 50,000 JSON documents into the container and it only took fractions of a second. It’s also very easy to auto scale up & down the throughput provisioning on the fly via code. You can check out the v3 SDK samples here
public async Task BulkTest(IEnumerable<Item> items)
{
var clientOptions = new CosmosClientOptions { AllowBulkExecution = true }; //Enable Bulk Execution
using var client = new CosmosClient(_endpoint, _authKey, clientOptions);
var database = client.GetDatabase(_databaseName);
var container = database.GetContainer(_containerName);
var requestOptions = new ItemRequestOptions() { EnableContentResponseOnWrite = false }; //Blind Upserts, don't get a hydrated response
await container.ReplaceThroughputAsync(10000); //On-the-fly Throughput Scale Up
var concurrentTasks = new List<Task>();
foreach(var item in items)
{
concurrentTasks.Add(container.UpsertItemAsync(item, new PartitionKey(item.PartitionKey), requestOptions));
}
await Task.WhenAll(concurrentTasks.ToArray());
await container.ReplaceThroughputAsync(1000); //On-the-fly Throughput Scale Down
}
Creating an Azure Cognitive Services Index
With the data safely in Cosmos, next we set about setting up the Azure Cognitive Services instance. Configuring this was a breeze. You can create a new instance directly from the CosmosDB Resource, and there’s a walk-through wizard to get the indexer setup using an hourly high-watermark check on the _ts timestamp
One thing that took a little bit of trial and error was the composition of the index in terms of what should be retrievable, searchable, orderable and facetable. More than once, we had to purge/drop and recreate the index as once it’s created you can’t modify the configuration. This is very manageable with a small initial dataset of a few hundred thousand products but I can imagine this would be slightly more work in production where we have ~10^7 product updates happening every day.
It’s worth mentioning that a number of my friends also recommended ElasticSearch as an alternative to ACS. It’s definitely on the bucket list to read up on, and one feature that ACS is sorely missing is the concept for Consistently Random Results which would have been nice in order to give a fair distribution of views to similar products across multiple retailers, or to build an “Inspire Me” function to return completely random results from a * search.
Serving the results
While I continued to get my arms around Cosmos & ACS, my colleague Daniel was busy getting the website up and running. For simplicities sake and since it was what we’re both most familiar with, the front-end was assembled using a vanilla .NET 4.8 MVC5 project with a bootstrap themes and some custom css/js.
The use case is pretty simple.
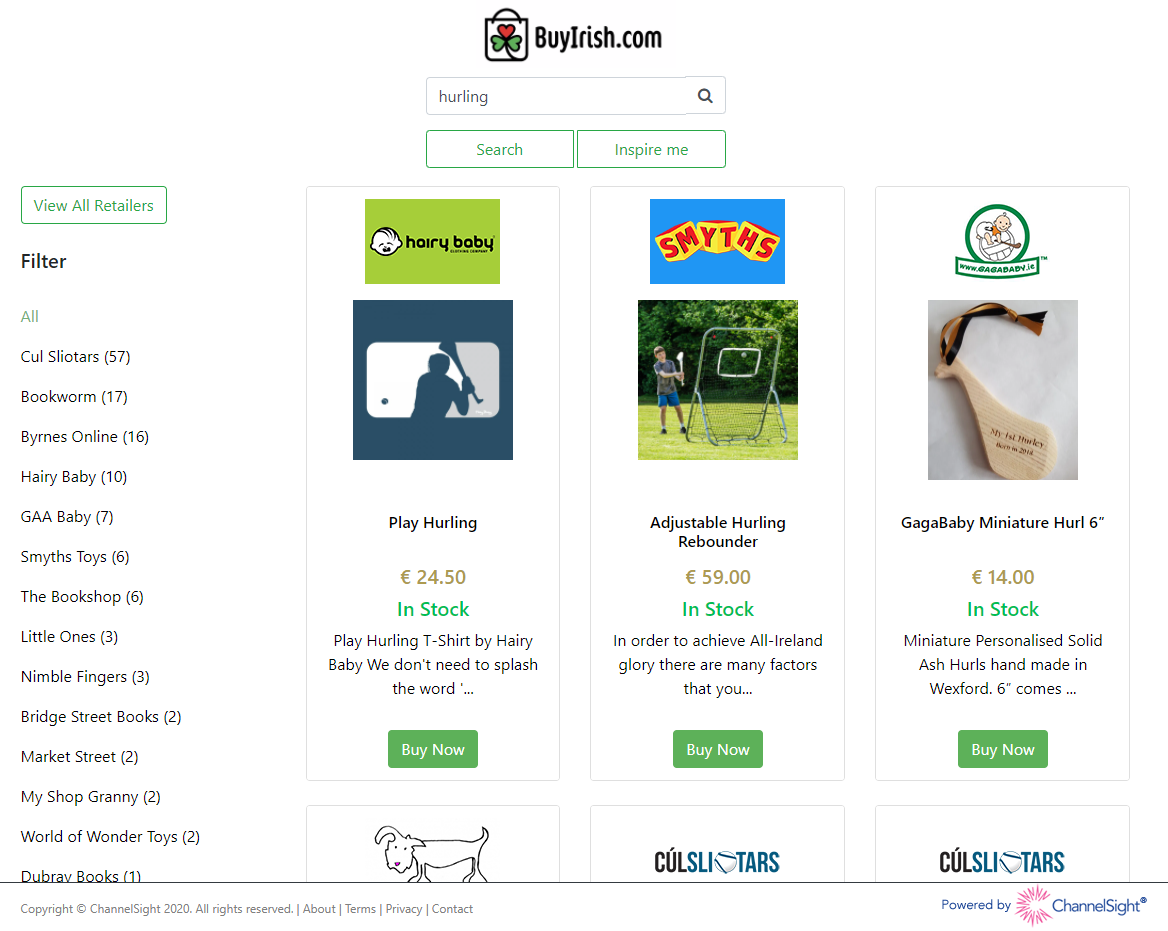
When the consumer arrives on the site, they can search for a term and ACS will return the most relevant products in order based on it’s internal scoring algorithm and a tweaked scoring profile we’ve provided. (More on that below)
The search query will return 6 results at a time and an infinite scroll javascript plugin handles fetching the next paginated set of product cards for that search term. In addition to the search results, the ACS response contains a facet result list based on the retailers that carry those products. These are displayed on the left hand side (including a result count per retailer), and if the consumer wants to filter to just that retailer they can click to filter. Finally, the consumer can also press “Inspire Me” and a random keyword will be chosen to provide a selection of different products.
Tweaking the algorithm
After some initial testing we noticed some discrepancies in the results. The problem was that some retailers provided extremely verbose product descriptions which might repeat a search term multiple times, while another retailer with a more relevant product might only mention the term once in the product title.
For example, if a consumer searched for “ACME Phone” you might have 2 different products at 2 different retailers. The 1st product is more relevant, whereas the second will get a better hit-rate based on keyword prevalence.
| Retailer | Name | Tags | Description |
|---|---|---|---|
| Retailer 1 | ACME Phone | ACME, Phone | This is a phone |
| Retailer 2 | Phone Cover | ACME, Phone | Works with ACME Phone Model X, ACME Phone Model Y, ACME Phone Model Z, ACME Phone Model Q |
The solution was to provide a scoring profile which over-rode the weights for these results, and now gives a much higher weighting to term occurrence in the product name than in the product description.
Stats, Stats, Stats
We wanted to get some very lightweight metrics on two things initially.
- What are people searching for?
- What are people clicking on?
To achieve this, we created a very lightweight click handler in the app that performs the 302 redirect to the retailer site. Every product is assigned a GUID formed from a MD5_HASH of it’s product URL as it’s ingested into the system. This allows us to both confirm uniqueness for UPSERTS but also quickly retrieve the cosmos document from the click handler and redirect the consumer to the product details page URL.
var result = await _cosmosService.GetItemAsync(retailer, productId);
if (result != null)
{
var properties = new Dictionary<string, string>
{
{ "et", "click" },
{ "id", productId },
{ "pn", result.ProductName},
{ "rt", retailer},
{ "ts", DateTime.UtcNow.ToString() }
};
_telemetryService.TrackEvent("click", properties, null);
return Redirect(result.Address);
}
return null;
The statistics themselves are then persisted directly to App Insights using the Application Insights SDK as customEvents with a Dictionary of meta data attached.. This is a nice quick solution (ignoring the default 90-day data retention issue) as it allows us to write some quick kusto queries to see how things are performing.
We’ve also added App Insights and Google Analytics to the front end to capture generic usage information as well.
customEvents
| where timestamp > ago (8h)
| where name == 'click'
| extend retailer = tostring(tolower(customDimensions["rt"]))
| extend product = tostring(tolower(customDimensions["pn"]))
| summarize sum(itemCount) by retailer // or by product, or both
| order by sum_itemCount desc
Some outstanding bugbears
One this which is still causing some head-aches is the ability to use Fuzzy Search. Azure Cognitive Services support the Lucene Query syntax. It should be possible to use keyword modifiers like ~ to specify fuzzy matching on certain words. This however led to spurious results. While beneficial for searches like tshirt~ to find results for t-shirt, it caused much poorer results for mis-spellings or keywords that clearly weren’t covered by any retailer. hurling~ led to hits for halflinger horse related products, and attempting to supply numeric modifiers like hurling~1 tanked the results entirely.
The //TODO List
These type of hackathon projects are great. They really highlight how quickly you can get something live. But they also quickly highlight why doing things right in a maintainable fashion is important. Right now this solution is missing a lot of “little” things which when combined together add up to a far more mature solution. We’ll see how things go over the coming days and weeks and maybe if it gets some traction, we’ll revisit to look at the following.
- Add CI/CD and a build/release pipeline to automate the deployment
- Setup a non-production environment for testing
- Add support for Soft-Deletion to Cosmos & ACS
- Add support for selective re-running of specific retailers
- Move the ETL Console Tool -> Azure Functions
- Make the Search a little more robust and forgiving to spelling mistakes/relevancy issues
- Add additional horizontally scalable instances
- Swap out the free 90 day SSL for a WildCard SSL Cert (or better a LetsEncrypt config)
- Add App Insights Continuous Export + Stream Analytics to get Click/Search data into our Synapse environment
- Migrate the web app from .NET Framework + MVC5 => .NET Core + MVC6
- Migrate the static content to Blob Storage
New Tech is Fun
Overall, this was a fun little project. It’s always nice to get out of the day-to-day JIRA Backlog and explore some new technology and I can definitely see us having a use for Azure Cognitive Search at some point in the future on our product roadmap. Thanks to everyone who chipped into to get it built. Daniel P, Alan, Daniel G, Bogdan, Dorothy, Enda & John.
Eoin Campbell